AudioLCM Overview
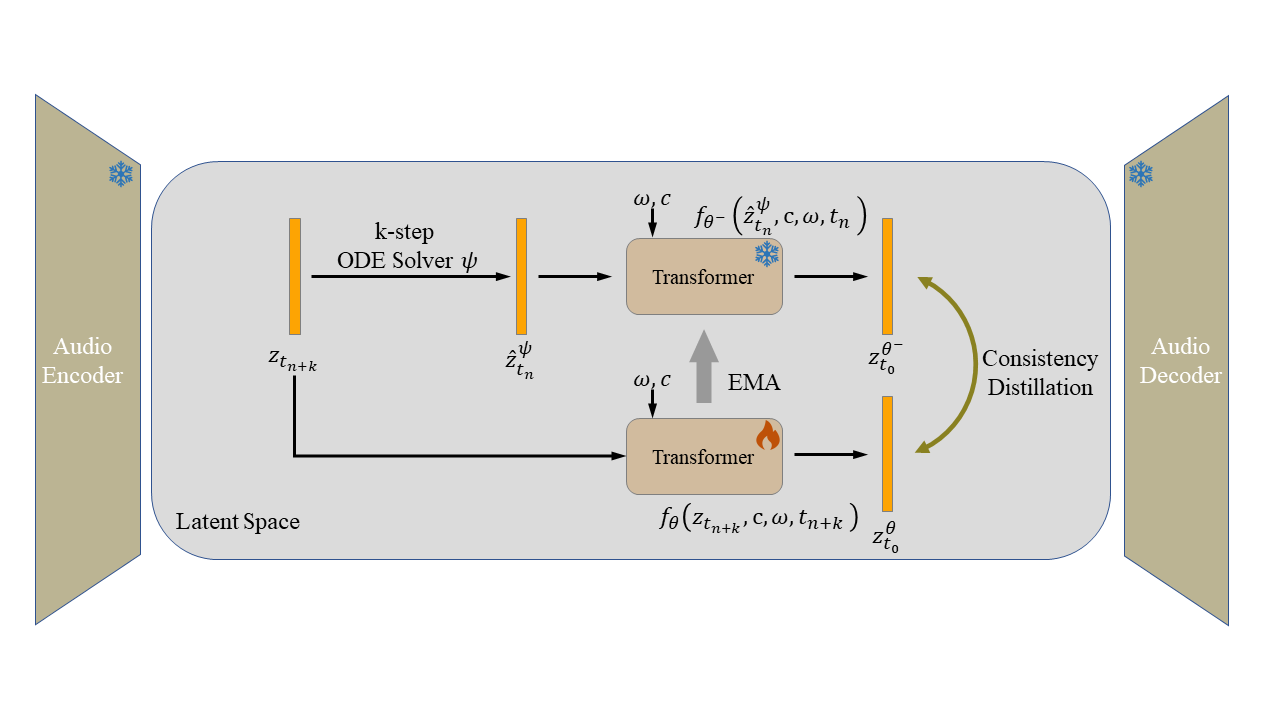
An illustration of EchoSpeech. AudioLCM propose the Guided Consistency Distillation with k-step ODE solver. c is the text embedding and 𝜔 is the classifier-free guidance scale.
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
Abstract. Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. Unlike prior approaches that address noise removal through iterative processes, AudioLCM integrates Consistency Models (CMs) into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-audio generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
An illustration of EchoSpeech. AudioLCM propose the Guided Consistency Distillation with k-step ODE solver. c is the text embedding and 𝜔 is the classifier-free guidance scale.
| Text Prompts | Ground-truth | AudioLCM | Teacher | Make-an-audio2 | AudioLDM2 | Tango | AudioLDM | Make-an-Audio | AudioGen |
|---|---|---|---|---|---|---|---|---|---|
| Text Prompts | Ground-truth | AudioLCM | Teacher | AudioLDM2 | MusicLDM | MusicGen | Riffusion |
|---|---|---|---|---|---|---|---|